You certainly have heard of a company named Google. The IT giant was among the first pioneers of Site Reliability Engineering (SRE)
Before that, and because Effective SRE is highly related to the Digital Transformation challenges, let us remind you of the 3 pillars of the Digital Highway, our blueprint for continuous and reliable continuous software delivery:
- Cloud-Native and AI-driven Continuous Delivery Pipeline that describes the toolchain required to achieve a high release frequency
- Cloud-Native and AI-driven IT Operations (AIOps) which provides the fundamentals for a highly automated, efficient operational platform
- Effective SRE-Centric Operating Model
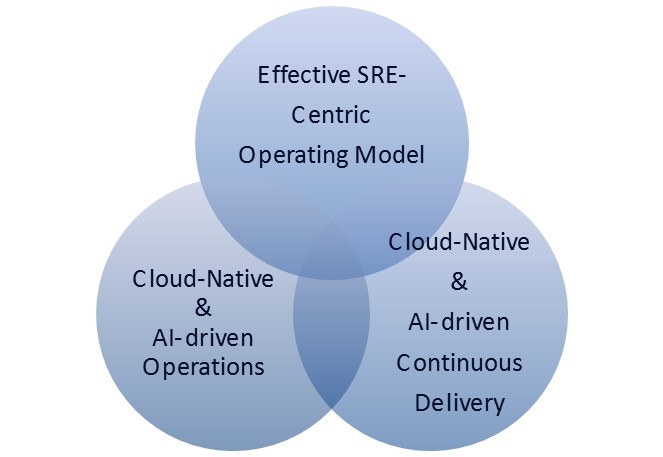
SRE-centric Operating Model for a successful Continuous Delivery Pipeline
This pillar is about the operating model required to co-build, pilot, operate, maintain and continuously improve the digital highway for continuous software delivery and operations.
While many organization and experts are referring to DevOps as operating model, we, at Digital Architects Zurich, think that is not sufficient to respond to modern challenges. In reality, DevOps focuses on how to extend the agile principles and culture to quality assurance and operations. It tends to assign operations responsibilities to development teams. However, the development teams will still be struggling to tackle the following complex practical three-dimensional “Ops” challenge:
Assuring stringent Service Level Objectives in a high frequency Continuous Delivery Environment and while continuously improving the Operations Efficiency.

This is where the SRE approach is complementary and compliant to DevOps, as it brings practical solution to the above introduced “Ops” challenge by applying software engineering skills to it.
Our main intention behind conceptualizing “Effective SRE” is to industrialize the SRE approach and make it accessible (i.e. democratise it) to any organisation looking to build the Digital Highway for Continuous and Reliable Software Delivery.
In order to understand what “Effective SRE” is about, let us have a look first at the fundamentals and roots of SRE.
The fundamentals and roots of SRE
Software Reliability is a non-functional quality attribute which is defined as the ability to continue to operate under predefined conditions. Availability is part of reliability and is expressed as the ratio of the available system time to the total working time.
Software Reliability Engineering (SRE) started as a modelling and prediction discipline in the early 1970s. After that, due to the increasing Software complexity, it evolved to more measurement, testing, monitoring and operation involving mainly QA, Performance Engineering and system administrators by the late 1980 and early 1990s.
SRE at Google (2003-2016, see references) further introduced such concepts and adapted them in order to cope with their extremely high scalability, availability and efficiency targets. The solution was adding THE key fundamental concept of error budget to tackle the trade-off between release frequency and feature delivery speed on one hand and operations stability and other SLOs on the other hand.
At Google, the SRE role has been defined as following : “In general, an SRE team is responsible for: the availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning of their service(s).”
The Google approach for SRE has been detailed in several books and articles where key principles (error budget, eliminating toil…) and practices (data centre load balancing, being on-call…) have been explained. For many organisations and teams, such publications were a starting support to discover SRE and think about its challenges and ways of implementation in different environments.
Effective SRE by Digital Architects Zurich: Definition and Scope
As said before, the trade-off (SLO vs. Delivery Speed) presented by Google in 2003 is nowadays the daily-business challenge of many organisations seeking digital transformation.
Many organisations are looking nowadays to adopt and deploy SRE as operating model and as new discipline for their Digital, DevOps or Cloud Operations. However, they have many questions on how to apply the SRE principles and practices from the books into their context. In fact, despite the major contribution of Google to adapt the original software reliability concepts through basic trainings and several publications, the adoption of SRE from the books to the specific context and environments of several organisations has been quite challenging.
Therefore, we have developed, at Digital Architects Zurich, the “Effective SRE” as a practical method that organisations can use for a step by step adoption and roll-out of SRE.
Digital Architects Zurich define Effective SRE as follows:
”The application of a systematic, holistic, disciplined approach to the definition, evaluation and cost-effective assurance of Service Level Objectives in the context of High-Speed Software Delivery, usually required as a central capability in Digital, DevOps or Cloud Transformations Roadmaps”.
We have designed the “Effective SRE” as a practical guide for organisations looking to adopt SRE. Combining Google best practices with our 20+ years’ experience in industrializing adjacent topics (such as Performance Engineering, Continuous Software QA, Unified Monitoring…) is our sauce to it. We centre our conceptualization and application of “Effective SRE” around the following objectives:
- Clear and structured set of activities required to design, pilot/control and operate the digital highway (Cloud-Native Continuous Delivery Pipelines and Operations)
- Reducing complexity and increasing efficiency by leveraging emerging Observability/Open Telemetry/Open Tracing Standards, AI, Cloud-native stacks and CI/CD tooling capabilities
- Clear roles, profiles descriptions and related modular trainings which can be adapted to the organisation context (maturity, size, roadmap…)

In more concrete words, the “Effective SRE” (defined by Digital Architects Zurich) scope covers:
- Co-Build, Maintain & Operate the Cloud-Native & AI-driven Continuous Delivery Pipeline.
- Co-Build, Maintain & Operate the Cloud-Native & AI-driven IT Operations (Observability and Open Telemetry -based monitoring, tracing & streaming, AIOps, Alerting, ChatOps) .
- Co-Build, Maintain and Operate the SRE Cockpit incl. SLO-Monitoring-, Continuous Delivery-, & Emergency-Status Dashboards to enable continuous feedbacks to the depending processes: incident-, change- & release-management.
- On-board & Support applications on the “Digital Highway” (Cloud-Native & AI-Driven CD Pipeline & Operations).
In upcoming blog posts, we will explain in more detail the secret sauce of the industrialized “Effective SRE” approach of Digital Architects. We will focus especially on the “Effective SRE” dimensions (SLO, Speed, Efficiency), the key “Effective SRE” principles (error budgeting, automation, adoption culture and others) and “Effective SRE practices (architecture, implementation and operation).
Foot notes/References:
- Site Reliability Engineering (Beyer, Jones, Petoff, Murphy, 2016).
- The Site Reliability Workbook (Beyer, Murphy, Rensin, Kawahara, Thorne, 2018).
- Site Reliability Engineering – an Overview (Digital Architects Zurich, 2020).
- Definition of Software Reliability (ScienceDirect, 2020).
- Blueprint for reliable and continuous software delivery (Digital Architects Zurich, 2020).