What if we told you that the only thing keeping your business from success is Reliability?
A simple recipe of two main ingredients can define a company’ success and growth: The balance between new features and reliability.
Trustworthiness, the ability to deliver a reliable product, predicting incidents before they happen and putting customers’ business stability at the center of the frame are the main keywords here. More companies are realizing the importance of implementing reliability to achieve success, growth, and customer trust.
Everyday, we notice an increasing demand for Site Reliability Engineers (SREs) whose key role focuses on the systems’ Reliability. As a matter of fact, SREs are projected to be in the TOP 10 of in-demand jobs in 2021, according to LinkedIn’s emerging jobs report.
This said, what is Reliability and how can we conceptualize it?
The most common misconception about reliability is that: Reliable product = error-free product. Yet, there is no such thing as 100% Reliability, as we explained in our “SLO engineering and Error Budget” blogpost. In IT, with service performance and service availability gaining more and more traction, reliability’s definitions are all over the place. At the end, all of them converge to say that reliability is about designing a robust architecture that will prevent failures you did not foresee.
Achieving 90% (72h not available within 30 Days!!!!) of availability or more might be a challenge if you do not re-architect your whole infrastructure around reliability.
Architecting Reliability
1/ Implementing SLIs and SLOs
It is literally impossible to design a robust system if we don’t have the adequate consciousness about our goals. Implementing a meticulous SLA is a crucial step to avoid breaches. The main goal is to consider what is an acceptable failure and what is not.
A good practice would be to set two different SLOs, an external SLO, agreed with the customer, and a stricter SLO, fixed internally by the team and for the team. Having a stricter SLO would grant lower chances to breach the external SLO, set by the customer and assert more room for errors to be fixed.
After we define our SLAs, SLOs and SLIs we would need to define which components of our system we want to make reliable.
2/ Monitoring your metrics
A famous old-saying by Desiderius Erasmus states that “Prevention is better than cure”. We could not find a better description of what is the philosophy behind architecting your system’s reliability.
SREs dedicate the majority of their workload towards preventing errors before it impacts customers. Using Real-time monitoring tools is an asset to make your systems become more reliable. It gives your teams the possibility to:
- Overview of the current health of your applications
- Prevent errors and diagnose issues
- Understanding customer’s behaviour
- Receiving real-time alerts
Investing in monitoring tools and in SREs becomes then a key for every company that wants to win customer’s trust.
3/ Operations Efficiency
Reliability is not just about building a robust system to avoid incidents; making sure that even during an incident there is a structured plan to follow or (incident management system) is a significant aspect of architecting reliability.
What are the needs for an efficient Incident-management?
- Emergency Response: also known as MTTR is the amount of time dedicated to bringing the system back in a green state prior to an incident.
- Separation of Responsibilities: to avoid any decrease of efficiency during an incident, it is crucial to clearly define the roles of each member.
- Having a live incident state document that can be editable by the different team members handling the incident. Retaining such information can be useful for post-mortem analysis.
Being on-call is as well a vital aspect of operations efficiency. Well trained teams know that the key of a successful on-call is: balance.
Having balanced on-calls, in quantity and/or in quality is a crucial step in operation efficiency.
In the Google’ Site Reliability Book, we define balance in quantity when the SRE team can invest at least 50% of their time into engineering, 25% on-call and the rest of the time on other operational work. To limit the number of night shifts during unpredictable incidents, it is best to use the “Follow the sun” method which is a way to pass the workflow to teams working on different time zones.
As for the balance in quality, it is mainly about the ability for an engineer to write post-mortems after an incident or to follow up with any other activity related to the incident.
Implementing fault tolerance into your System
Before diving into the fault tolerance implementations, it is crucial to first clarify the confusion between high availability and fault tolerance.
While high availability and fault tolerance’s main common goal is to ensure system continuity there are some fundamental differences.
Let’s say your server is down and you need to redirect your users to a new instance. In high availability, the creation of a new instance, containing the replica of the previous environment might take some time, we call it downtime.
In fault-tolerant systems there is no downtime. Whenever a server stops working, users will immediately be redirected to an operational instance without even noticing what is happening behind the scenes. Unlike high-availability, fault-tolerant systems rely on power supply backups that can take over during electricity fails.
Still, a good number of companies go the high-available systems route, for obvious reasons related to cost, allowed downtime and business needs. The migration towards cloud-services and systems availability being more and more vital in highly competitive cloud environment, should propel fault-tolerance as the best and more reliable way to go.
To keep it simple, in high availability systems we can afford few seconds of down-time while in fault-tolerant systems down-time is not allowed. That is why a system can be high-available but not fault-tolerant.
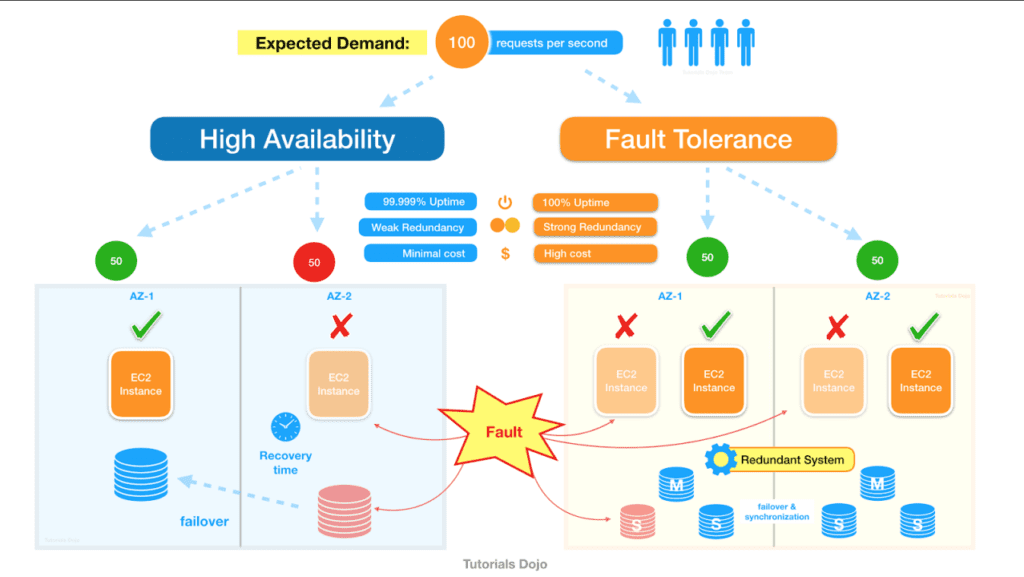 High Availability versus Fault Tolerance systems (Jon Bonso, 2020)
High Availability versus Fault Tolerance systems (Jon Bonso, 2020)Now, how can we build fault-tolerant architecture?
To tackle this challenge, the first question you must ask yourself is how many running instances do I need? Based on the number of instances, you will have an idea of the number of availability zones.
For instance, let’s say Digital Architects Zurich developed an application that needs eight running instances.
In a highly available system, we would need 2 availability zones and several instances. As for a fault-tolerance architecture, we will need to have eight running instances even if one availability zone goes down. This means, we could have 12 running instances, 4 instances in each availability zone. This way, if a zone goes down, we would still have 8 instances up and running.
By proactively preventing errors, your company will witness a more reliable product leading to a stronger customer trust.
If correctly implemented, a company could benefit from these steps. That said, it is important to assess the different reliability approaches to adopt from the initial stages of design, since it is easier and less stressful in terms of resources to start from nothing then to re-architect.
Even though some companies are still reluctant to change their culture, it is important to overcome the resistance to change and adapt accordingly to the customer’s needs. Going the fault-tolerant architecture route is a huge step in that direction.
Foot notes/References:
- Reliability Engineering Book (By Kailash C. Kapur, Michael Pecht, 2014).
- Design for Reliability Book (by Dev G. Raheja, Louis J. Gullo, 2012).
- Site Reliability Engineering – an Overview (Digital Architects Zurich, 2020).
- Honeywell Annual Reports. Honeywell Inc. 22 July 2002.
- Site Reliability Engineering Workbook, Chapter 4 – Monitoring 2018 https://sre.google/workbook/monitoring